
Editor's note: This story first appeared in the March 2024 issue of Chess Life Magazine. Consider becoming a US Chess member for more content like this — access to digital editions of both Chess Life and Chess Life Kids is a member benefit, and you can receive print editions of both magazines for a small add-on fee.

It used to be so simple.
They had different names, but way back in the 20th century, the best chess engines were quite similar. They used the same search method — a tried-and-true programming technique called alpha-beta pruning. They evaluated the terminal positions by counting up the material, and then modifying the scores for hand-coded positional factors like square control, pawn structure, and safety. And they only ran on one core. (Your computer likely only had one core back then.)
Naturally there were some stylistic differences. Fritz would value things differently than Junior, while Shredder and Hiarcs were not nearly as speculative as CS Tal. But generally speaking, you could just get the top-rated engine and feel confident in your understanding of the evaluations it spit back out. A score of +1.30 meant that White was up a pawn with a bit of an additional positional advantage. The engines were strong tactically, but pretty weak positionally, so their advice could not always be trusted.
Since then, things have changed.
Near the turn of the century the first multi-core processors became available, making search faster but also (because of parallelization) unpredictable. Repeating a search on multiple cores will often give a different move and evaluation.
Search algorithms were improved. Searches got much deeper with new techniques for pruning unpromising lines, making the engines more “selective” and stronger.
Evaluation functions also became much more sophisticated. Material advantage, for example, started to be treated differently based on game stage. If, for example, you are up a healthy, undoubled pawn in a pawn ending (with at least two pawns for the better side), and there is no compensation for the defender, you’re usually winning quite easily unless the defender has some obvious tactical save. Often it takes just minimal skill to promote the pawn and deliver checkmate, so the result is that a pawn-up endgame may actually be more easily won than a queen-up middlegame.
This is one of the reasons that strong engines began in those years to show values far above +1.00 for such endgames, while returning scores of below +1.00 for a clean pawn advantage in the opening. While such positions are theoretically winning, all being equal, the defending side always has decent drawing chances, especially in human play.
But the first big breakthrough came in 2017 with AlphaZero. Using a different processor type (GPUs instead of CPUs), neural networks for evaluation instead of human-derived rules, and a radically different type of search (“MCTS” or Monte Carlo tree search) that is probabilistic in nature, it was able to crush the best classical engines of its time.

AlphaZero was never made public, but soon enough an open-source alternative called Leela (Lc0) was launched. Leela was designed on the principles underlying AlphaZero, and was nearly identical, save the fact that it could run on consumer hardware. It played much different chess than the top alpha-beta engines of the day, somewhat weaker tactically but much stronger positionally, and for a couple of years it was the engine of choice for anyone who could afford a computer with a powerful GPU.
Then came the next big breakthrough, the one whose effects we are witnessing now. Programmers in the Shogi (Japanese chess) world developed smaller neural networks suitable for CPUs that replaced their evaluation functions. These “neural networks updated efficiently,” or NNUEs, were remarkably successful for Shogi engines, and it was claimed that this programming technique would add 100 rating points to the top engines.
Most engine enthusiasts were skeptical, but with my experience as one of the top non-Japanese shogi players, I was quickly convinced by the radical strength increase this new technique wrought in Shogi engines. Soon chess programmers began to tinker with NNUEs, and by the end of 2020, both Stockfish and Komodo had seen that predicted 100 Elo point boost. Later enhancements added greatly to that gain.
The NNUE evaluation function can be seen as a hybrid between classic engines and those like AlphaZero or Leela. It runs on the CPU, and uses the traditional alpha-beta search to zoom through analysis, but it uses neural networks trained on high-quality data over many iterations to work as its evaluative brain, determining the “score” of the position. Using training techniques not unlike those of Leela, the result is a much smaller network that may not be as “smart” as Leela’s, but it does not burden the CPU and slow search down. The result is an engine that retains nearly all the tactical strength of classical engines, while also keeping much of the positional strength of Leela.
These NNUE engines quickly took the lead in engine tournaments and rating lists, and today all the top-ranked engines use neural networks for their evaluation functions. CPU based engines like the open-source Stockfish are currently in the lead, followed by Komodo (which I worked on for years) and Torch, a new, private engine from Chess.com. The relative placement of Leela among these three depends greatly on hardware and test conditions.
One of the curious effects of the shift to NNUEs was a disconnection between evaluation and material. By the time of Stockfish 15, for example, users would encounter positions that would have gotten a +1.00 evaluation in the old days — a simple pawn-up with no positional advantage for either side in the opening — and be surprised when Stockfish reported a score of +2.00 or more. Other positions that looked like marginal, difficult wins to the human eye would receive absurd evaluations like +5.
A pawn was no longer a pawn. And users were getting confused.
Starting with version 15.1, the Stockfish community opted for a new standard, one that the other major engines have also adopted. Unmooring a strict relationship between material and evaluation, a score of +1.00 is now defined as a position where White is expected to win 50% of the games from that position, while Black will either draw or win the other half. There is some difference in how this standard is applied — Stockfish pegs this to move 32, while Komodo looks to the opening, and Leela applies it everywhere — but that is just a detail.
The main thing to know is that any evaluation above 1.00 means that the engine believes the position is more likely than not won with perfect play. A score between 0 and 1 means that the position is evaluated with advantage to one side, but more likely than not to be drawn with perfect play. Since it generally takes about a 0.7 pawn advantage to reach this 50/50 dividing line at the super-GM level, we might say that a clean pawn-up should show an evaluation of +1.4 on average — 1/0.7 = 1.43.
So how do we interpret these new evaluations, now that they are not strictly speaking in pawn units?
I propose a simple way to think about them, one that might not be technically correct, but is good enough for over-the-board use.
If the evaluation is above +1.00, the position is likely already won with perfect play. The number just indicates how certainly this is so, with higher numbers showing increasingly more certainty. Anything above +2.00 indicates high confidence in the winning assessment.
Note that this does not tell us anything about the ease of winning. The engine might report one position to be +10, but you might have to find five consecutive brilliant moves to justify the evaluation! This is especially true with the NNUE engines; with Leela, there is more of an attempt in the search to assess the difficulty in finding the win. (More on this later.)
If the evaluation is between 0.00 and 1.00, you should think of it as representing the probability that the game will likely reach theoretically winning status before reaching total equality status, given that the players are human and likely to err.
For example: if the position is evaluated as +0.50, it should be equally likely to reach 0.00 (totally equal) or +1.00 first, given the random errors made by humans. (This would not be true if the potential errors were tiny, as they are in engine versus engine play.) If the position is +0.80, it is obviously more likely to wander up to +1 than down to 0.00.
One of the practical ramifications of this line of thinking, and one that we will discuss extensively in the second installment of this article, is engine evaluation and opening choice. Someone playing Black in ICCF correspondence chess, where engine us is fully legal, might be willing to play positions that the engine evaluates as -0.70, knowing that it is probably drawable by the engine. A human playing over-the-board chess should avoid such positions, unless they believe that the positions are harder to play in practical terms for the opponent than themselves.
This is where human judgment becomes important. Consider a situation where White sacrifices a pawn for superior development. Is it easier to find the right moves for White with the dynamic advantage, or for Black with the static / material advantage? Is the defending side able to find the best defensive ideas easily, or are they counter-intuitive? There is no general answer; any assessment is necessarily concrete and position-dependent.
It’s also important in this context to understand how the top engines are different from one another, and how the hardware used can affect what the engines output.
Most serious players use Stockfish now for analyzing games, since it generally tops the rating lists and wins elite engine tournaments. Because it is open-source software and can run on many different kinds of processors, it’s everywhere — on cellphones and iPads, on laptops and “in the cloud.” That kind of ubiquity, however, can obscure the truth. The specific version of Stockfish being used, and the hardware it runs on, can affect the quality of its analysis.
The Stockfish on your cellphone may be Stockfish 11, which was the last version with a human-crafted evaluation (HCE) and without NNUE. Chess.com offers Stockfish 16 lite (using legacy HCE) and “normal” Stockfish 16, along with Komodo lite (HCE only) and two versions of their private engine Torch: one with a full-sized NNUE evaluation, and one with a distilled, smaller version.
It’s much the same on Lichess, where users can choose between Stockfish 11 HCE, Stockfish 14 NNUE, and two versions of Stockfish 16: a lite version with a 7 megabyte evaluation network, and one with the standard 40 megabyte NNUE evaluation file.
Users can adjust the number of lines being analyzed on both Chess.com and Lichess. They can also modify the number of threads / cores (most modern CPUs offer multi-threading cores) being used for analysis, and the size of a modest hash table, on Lichess. But to do any of this, a user must actively enter the settings dialog, when the fact of the matter is that few users will go to these lengths. Why bother when you can just turn the engine on and watch the analysis start?
Up-to-date engines offer the most accurate analysis, and more powerful hardware allows you to get that accurate analysis faster. The Stockfish that runs on your phone will be very slow compared to what you will get on a PC with four, eight, or 16 cores. It’s true that you can get nearly the same quality analysis using one core on your cellphone as you could on a 128-core / 256-thread Threadripper, but it would take about 100 times as long. What would take five minutes to find on your phone would take just seconds on a fast PC.
The number of cores being used can also, in marginal cases, affect the analysis itself. Stockfish is programmed to prune more or less moves from its search depending on how many threads it has available. When running on just one thread, it will do much more pruning than it will running on 16 threads. With less pruning comes more chance that the engine can accurately assess moves that it would otherwise initially reject.
What does all this mean? Speed is linked to quality in computer chess. More cores means more speed, and up-to-date engines can take full advantage of increased computing power. Stockfish 11 on your iPad is good enough for a tactical game review, but if you want really high-quality positional suggestions, you should be using Stockfish 16 or later, or Dragon 3.3, running on a good PC.
Here’s an example where the computing power mattered.
one or the other
This is a pivotal moment that two annotators — YouTube’s Agadmator and Colin McGourtey for Chess.com — overlooked. In both cases I suspect it was because they didn’t let the engine run long enough.
Here the default engine on Chess.com, Torch, initially evaluates both 28. ... Kh7 and 28. ... Kh8 as roughly equal. Only when it gets to depth 34 or higher does it recognize the difference, and reaching that depth takes time on a laptop or portable device. A quick scan or automated analysis would not pick it up.
to take or not to take
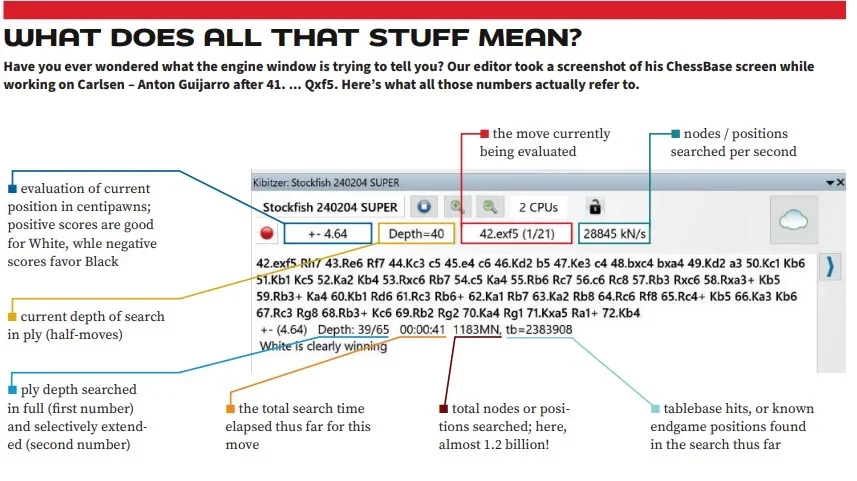
Moving on: what value are tablebases? (Tablebases are presolved endgame databases that engines can use to accurately assess positions with up to seven pieces in the search.) In general, I think they are overrated, because they don’t raise the quality of engine assessments more than a few Elo points — engines play the endgame very well now without them. But they can come in handy. Consider this position from a recent game between Magnus Carlsen and David Anton Guijarro.
If you were to analyze this game on 365chess.com with their embedded version of Stockfish 16, you would (wrongly) believe that White was better but not necessarily winning after either 41. ... Qg7 (+0.37 at depth 42) or 41. ... Qxf5 (+0.72 at depth 42). After testing, I believe that the 365chess engine has the NNUE evaluation turned off but does not disclose this fact.
The embedded Stockfishes (which do not include tablebases) on Lichess using four threads and a 512 megabyte hash table tell a different story: +0.4 and +2.3 at depth 42 for Stockfish 16, and +0.3 and +2.9 for Stockfish 16 lite at depth 45. They see 41. ... Qxf5 as a serious mistake.
Running on 16 threads with a 16 gigabyte hash table, the latest Stockfish equipped with six and selected seven-man tablebases is more critical still, deeming 41. ... Qg7 to be well within the drawing range at +0.35 (depth 40), while 41. ... Qxf5 is an egregious error at +4.64 (depth 40).
The point? The accuracy of engine analysis grows with increased resources. The Stockfish embedded in a website might only run on one core with limited hash tables, resulting in misleading output. More processing power and longer search time can overcome these problems, and the NNUE evaluation function adds to analytical accuracy immensely.
(In case you were wondering: in the game Anton Guijarro took the queen with disastrous results.)
What about Leela? Despite it needing specialized hardware for optimal use — an RTX 2060 graphics card or higher — I think it offers two advantages over Stockfish. The first is that it can analyze multiple lines without any cost. Analyzing in “multi-PV” is an important tool, as showing the difference between the first- and second-best moves can immediately point out forced continuations. With Stockfish, this can slow the search significantly. With Leela, there is no computational cost in doing so.
The second benefit is potentially more important. Users should understand that Stockfish and Leela are trying to answer different questions in their searches. Stockfish tries to find the strongest moves for both sides (assuming perfect play) at every turn, while Leela, using its “Monte Carlo” style search, inquires after the best moves against good but unpredictable play.
One common way that this difference shows up is the famous 0.00 evaluation from Stockfish, which is given when Stockfish “believes” that best play ends with a draw by repetition. Leela proceeds differently. Even if it expects a repetition, the side that more likely to go wrong will usually show a mildly negative score.
Imagine a situation where White is a rook down, looking for a difficult perpetual that requires accuracy over a number of checks. Leela might evaluate this as -0.10, indicating a probable, if non-trivial, draw where Black is the only one who might win. This is very helpful for a practical player, although it can be annoying to see a -0.03 evaluation when the perpetual is obvious.
Four versus three
Understanding engine output, and how Stockfish is different from Leela, is very helpful for a practical player. With experience, you will learn which evaluations indicate draws you can readily spot, and which are more difficult. There are countless positions in chess that are clearly drawn with perfect play, but which are also clearly easier for one side to win. Stockfish will show all zeros in such positions, while Leela will usually return a decent plus score for the “easier to play” side, even after a long think. Here is a simple example:
This four versus three rook endgame is known to theory as a draw, but it is well worth White’s time to play out, as Black has to keep finding good moves to draw. On my modern laptop, not using tablebases, the current version of Stockfish shows a +0.04 score almost immediately, dropping to 0.00 after a couple of minutes. The current Leela shows +0.19, and +0.18 after a few minutes time.
Stockfish is telling us what the result of the game will be with 3500-level play, while Leela is telling us the likely result of the game with “only” human GM-level play. Stockfish says “draw,” while Leela says “should be a draw, but Black may lose if they don’t play accurately.”
It’s for this reason that, for most over-the-board players, I recommend using a Monte Carlo style engine like Leela if you have a modern GPU, and a MCTS-enabled engine like Komodo if you don’t. Naturally you can (and should!) consult Stockfish as well, but you will have to make your own judgments about the difficulty of the moves for both sides.
I hope you have learned something about today’s chess engines in this article. Next month, we’ll apply this knowledge to opening study, learn to interpret what modern engines are telling us about key opening tabiya, and try to deduce some principles of contemporary opening play.
A Glossary of Terms
Cores / threads – modern processors differentiate between physical cores and “threads,” or virtual instruction streams. Some cores are singled threaded, and some are dual threaded.
CPU – central processing unit; the calculative engine in your computer.
Evaluation – the part of a chess program that assesses each position in a game tree and assigns it a numerical value.
GPU – graphics processing unit; generally speaking, your graphics card.
Hash table – the memory used by a chess engine to store evaluations and refer to them in search.
HCE – human (or hand) crafted evaluation; the older “brain” for chess engines, using recognizable positional terms to score positions.
Neural network – an AI method of machine learning that trains computers to deal with data inputs through intensive analysis of training data. They are used for evaluation functions in chess engines.
NNUE – “neural network updated efficiently;” the new “brain” for CPU-based chess engines.
Search – the part of a chess program that sorts and chooses moves in a game tree.
Parallelization – a situation where one algorithm or function “runs” on multiple cores or threads.






Categories
Archives
- January 2026 (9)
- December 2025 (27)
- November 2025 (29)
- October 2025 (39)
- September 2025 (27)
- August 2025 (29)
- July 2025 (43)
- June 2025 (25)
- May 2025 (24)
- April 2025 (29)
- March 2025 (29)
- February 2025 (20)
- January 2025 (24)
- December 2024 (34)
- November 2024 (18)
- October 2024 (35)
- September 2024 (23)
- August 2024 (27)
- July 2024 (44)
- June 2024 (27)
- May 2024 (31)
- April 2024 (51)
- March 2024 (34)
- February 2024 (25)
- January 2024 (26)
- December 2023 (29)
- November 2023 (26)
- October 2023 (37)
- September 2023 (27)
- August 2023 (37)
- July 2023 (47)
- June 2023 (33)
- May 2023 (37)
- April 2023 (45)
- March 2023 (37)
- February 2023 (28)
- January 2023 (31)
- December 2022 (23)
- November 2022 (32)
- October 2022 (31)
- September 2022 (19)
- August 2022 (39)
- July 2022 (32)
- June 2022 (35)
- May 2022 (21)
- April 2022 (31)
- March 2022 (33)
- February 2022 (21)
- January 2022 (27)
- December 2021 (36)
- November 2021 (34)
- October 2021 (25)
- September 2021 (25)
- August 2021 (41)
- July 2021 (36)
- June 2021 (29)
- May 2021 (29)
- April 2021 (31)
- March 2021 (33)
- February 2021 (28)
- January 2021 (29)
- December 2020 (38)
- November 2020 (40)
- October 2020 (41)
- September 2020 (35)
- August 2020 (38)
- July 2020 (36)
- June 2020 (46)
- May 2020 (42)
- April 2020 (37)
- March 2020 (60)
- February 2020 (38)
- January 2020 (45)
- December 2019 (34)
- November 2019 (35)
- October 2019 (42)
- September 2019 (45)
- August 2019 (56)
- July 2019 (44)
- June 2019 (35)
- May 2019 (40)
- April 2019 (48)
- March 2019 (61)
- February 2019 (39)
- January 2019 (30)
- December 2018 (29)
- November 2018 (51)
- October 2018 (45)
- September 2018 (29)
- August 2018 (49)
- July 2018 (35)
- June 2018 (31)
- May 2018 (39)
- April 2018 (31)
- March 2018 (26)
- February 2018 (33)
- January 2018 (30)
- December 2017 (26)
- November 2017 (24)
- October 2017 (30)
- September 2017 (30)
- August 2017 (31)
- July 2017 (28)
- June 2017 (32)
- May 2017 (26)
- April 2017 (37)
- March 2017 (28)
- February 2017 (30)
- January 2017 (27)
- December 2016 (29)
- November 2016 (24)
- October 2016 (32)
- September 2016 (31)
- August 2016 (27)
- July 2016 (24)
- June 2016 (26)
- May 2016 (19)
- April 2016 (30)
- March 2016 (36)
- February 2016 (28)
- January 2016 (32)
- December 2015 (26)
- November 2015 (23)
- October 2015 (16)
- September 2015 (28)
- August 2015 (28)
- July 2015 (6)
- June 2015 (1)
- May 2015 (2)
- April 2015 (1)
- February 2015 (3)
- January 2015 (1)
- December 2014 (1)
- July 2010 (1)
- October 1991 (1)
- August 1989 (1)
- January 1988 (1)
- December 1983 (1)