
Fritz is the granddaddy of commercial chess engines, the first to defeat a world champion in an “official” blitz game (Kasparov, 1992) and in a head-to-head classical match (Kramnik, 2006). While top players originally thought it a toy, Kasparov used Fritz 4 as part of his analytical process as early as the the 1995 match against Anand, where it proved invaluable in working out his 14. Bc2! novelty in the tenth game. For years careful readers could find reference to Fritz or “Fritzy” in the annotations to top-level games. But Fritz has fallen on hard times. Engine author Frans Morsch retired after the release of Fritz 13, and the Fritz franchise took a back seat to a series of new, more advanced engines: first Rybka, then Houdini, Komodo, and (especially) Stockfish. ChessBase struggled along with Fritz 14, a "skin" of the formerly private engine Pandix, while Fritz 15 and 16 were both rebranded and marginally improved versions of Rybka 4.1. None climbed the ratings charts, and none captured the public imagination. Now Fritz is back, and the 17th edition of this elder statesman of computer chess is once again at the forefront of chess technology. With “Fat Fritz,” ChessBase has published the first commercially available neural net chess engine. Neural Nets Traditional chess engines like Stockfish use human-tuned criteria to evaluate positions, and using ‘alpha-beta’ (AB) search methods, they methodically trim down the tree of possible continuations, focusing on promising lines while pruning away inferior options. Everything Stockfish knows comes from its human authors, and its precise mathematical evaluation of any position is easily accessible to end users, as are all the elements of its code. Neural networks (NNs) are different. One of the paradigm cases of artificial intelligence, neural networks are self-learning algorithms that effectively teach themselves how to do something. NNs are given immense amounts of data, and over thousands of interations, they train themselves to achieve expertise in a specific domain. While there have been different attempts to tackle chess with artificial intelligence techniques, it was only with AlphaZero that a real breakthrough was made. Pre-programmed with only the basic rules of chess, and using a general (non-domain specific) self-training algorithm, AlphaZero famously taught itself to play chess over the course of nine hours and 44 million self-play games. Periodically the algorithm would refine its network as the self-play proceeded, promoting tunable weights and network ‘layers’ that led to favorable outcomes, and demoting those that didn’t. Neural networks like AlphaZero also search differently than do traditional alpha-beta engines. While AB engines shear away branches of their search tree as they go deeper, NN engines spin out future game positions, evaluate them, and rank them probabilistically. More promising continuations get greater search attention, leading to lopsided search fields, and native evaluations are reported in terms of win percentages instead of centipawns.
 courtesy NIC
courtesy NICAlphaZero was a literal game changer, as the title of Sadler and Regan’s book suggests, but as a closed source, proprietary ‘black box,’ its direct effect on chess was limited. We have a few hundred games to look at, but because players cannot analyze with it, cannot test its moves in the marketplace of ideas, I would argue that its greatest legacy is in what it inspired. Leela Chess Zero (Leela) is an open-source project based on the ideas and pseudo-code underpinning AlpahZero. Like AlphaZero, Leela’s networks are created through pure self-learning, her knowledge drawn from millions of self-play games. It is fully community run, with enthusiasts from around the world donating time on their computers to help train the different networks. The best pure self-play network thus far (42850) is generally is to be on par with development versions of Stockfish, while a slightly modified net (T40.T8.610) won the 15th TCEC Superfinal. Current sixth series networks, still in training, are beginning to approach the strength of Stockfish 10. The great success of Leela has not gone unnoticed by leading players. Caruana’s seconds made great use of Leela in the days leading up to the 2018 World Championship match. More recently, Hikaru Nakamura told Jan Gustafsson during an interview at chess24 that he found Leela’s “differing viewpoints” refreshing. The for-profit chess world has also picked up on this innovation. “Fat Fritz” is the first commercially available neural net chess engine, and it is at the heart of the new Fritz 17 product. While there are other ‘novelties’ included with Fritz 17, Fat Fritz is certainly the center of attention. As such, we’ll focus on it here. Fat Fritz Created by Albert Silver and rooted in his earlier Deux X project, Fat Fritz is based on the Leela project, but with a twist. Pure reinforcement learning, where networks are grown using only self-play as a source, need not be the only way to create a strong neural network. Silver used “supervised learning” to train Fat Fritz: the engine was fed hand-picked data, mostly from MegaBase, correspondence games, and top-level engine battles. Reinforcement learning was then used to help refine the network and strengthen it. The result is a neural net engine that is of comparable strength to the top Leela networks, and that can keep pace with the most current development versions of Stockfish.






The Fritz 17 package includes:
- Four versions of Fat Fritz: RTX, CUDA, OpenCL, and CPU. Why four? Unlike traditional alpha-beta engines, neural net engines run on your graphics card or GPU. Some GPUs work better with Fat Fritz and Leela than do others:
- Recent Nvidia cards – the RTX 2000 series and GTX 1660 series – are best, as they are able to effectively use “fp-16” calculations, which Leela and Fat Fritz are optimized for.
- Less recent Nvidia cards still have CUDA cores, which also speed things up. This includes the GTX 1070, 1080, etc.
- AMD GPUs will run under the OpenCL framework.
- The CPU version is severely hamstrung, and cannot be recommended for serious use. If you have an Intel (integrated) GPU, you are best off using the CPU version.
- Fritz 17, a traditional alpha-beta engine. This edition of Fritz is a rebranded version of Ginkgo, a formerly private engine from Frank Schneider. The relationship between Ginkgo and ChessBase is not new, as it powers the “instant analysis” feature in ChessBase 15, but this is the first time that Ginkgo will be available to engine enthusiasts. It is very strong, if not in the same league as Komodo or Stockfish, and a definite improvement over Fritz 16.
- Leela is also installed with network 42850, generally considered the strongest pure self-learn network. This is not insignificant, as a lot of people (including titled players!) have trouble figuring out how to get Leela working on their computers. With Fritz 17, ChessBase has solved this problem. The installation process even calibrates the “opencl” version of the engine.
- A new GUI, including a handful of features new to ChessBase playing GUIs.
Evaluating Fat Fritz is a difficult task, as it involves two elements. An objective measure of strength is important, trying to determine how it compares to Leela, Stockfish, etc. But equally important is a subjective test. Does Fat Fritz provide interesting ideas? How do they differ from those of Leela and Stockfish? Let’s take each in turn before summing up. Objective tests I have had access to a beta of Fat Fritz for about two weeks, and according to my tests (Ryzen 7 1700 at 3.7Ghz, RTX 2060) Fat Fritz is competitive with the strongest Leela network – T40.T8.610, as used in TCEC – but is probably slightly weaker. I ran two different matches between FF and Leela at bullet time controls (2m + 1s) using the TCEC 16 openings. Leela won the first match 59.5-40.5 (24-71-5 for Leela), indicative of a 67 point Elo gap. I repeated the match using an updated beta version of FF, and while the gap was narrowed, Leela won again by a score of 56.5-43.5 (21-71-8 for Leela). 
 I then tested FF against the then-current development version of Stockfish. Using the TCEC 16 openings, I began a match between the FF CUDA engine and SF dev running on 4 cores at the same 2m +1s time control. One of the difficulties in testing AB and NN engines is that they run on different types of hardware; in limiting both in this way, I hoped to achieve a Leela ratio of about 1, so that their relative strengths would simulate that in the AlphaZero – Stockfish matches. Here the Leela ratio was 0.88, meaning that the hardware situation marginally favored Stockfish.
I then tested FF against the then-current development version of Stockfish. Using the TCEC 16 openings, I began a match between the FF CUDA engine and SF dev running on 4 cores at the same 2m +1s time control. One of the difficulties in testing AB and NN engines is that they run on different types of hardware; in limiting both in this way, I hoped to achieve a Leela ratio of about 1, so that their relative strengths would simulate that in the AlphaZero – Stockfish matches. Here the Leela ratio was 0.88, meaning that the hardware situation marginally favored Stockfish.  Stockfish was winning 39-23 (19-40-3 for SF dev) before I stopped the match, indicating a 92 point Elo gap in what is admittedly a small sample size. I stopped the match because I was beginning to suspect that short time controls were not to FF’s strength, and I wanted to see what would happen if I gave FF more time. I then ran a 20 game test match between FF and SF dev under the same conditions, using the first ten positions from the TCEC 16 openings and extending the time control to 7m + 3s.
Stockfish was winning 39-23 (19-40-3 for SF dev) before I stopped the match, indicating a 92 point Elo gap in what is admittedly a small sample size. I stopped the match because I was beginning to suspect that short time controls were not to FF’s strength, and I wanted to see what would happen if I gave FF more time. I then ran a 20 game test match between FF and SF dev under the same conditions, using the first ten positions from the TCEC 16 openings and extending the time control to 7m + 3s.  Stockfish led by a score of 13-7 (7-12-1) after 20 games, which represents a 108 point rating gap. Additional time did not help Fat Fritz here, and given the small sample size, I suspect that the rating difference in the two matches is within the margin of error. So I tried two final matches, using the strongest settings available to me for both Fat Fritz (cudnn-fp16) and SF dev (8 cores), and pairing them in two 100 game matches with the TCEC openings and time controls of (a) 3m + 2s and (b) 7m + 3s. The Leela ratio was 1.4, giving a small hardware edge to Fat Fritz.
Stockfish led by a score of 13-7 (7-12-1) after 20 games, which represents a 108 point rating gap. Additional time did not help Fat Fritz here, and given the small sample size, I suspect that the rating difference in the two matches is within the margin of error. So I tried two final matches, using the strongest settings available to me for both Fat Fritz (cudnn-fp16) and SF dev (8 cores), and pairing them in two 100 game matches with the TCEC openings and time controls of (a) 3m + 2s and (b) 7m + 3s. The Leela ratio was 1.4, giving a small hardware edge to Fat Fritz. 
 Here again Stockfish won. The 3m+ 2s match was much closer: 51-49 (20-62-18) in favor of the alpha-beta engine, despite the more favorable hardware situation for Fat Fritz. The 7m + 3s match also went to Stockfish, 56-44 (21-70-9). What does this all mean? My testing shows that Fat Fritz is not dramatically inferior to Leela and the latest versions of Stockfish, but all data from my machine indicates that Leela and Stockfish are stronger. Initial tests from CEGT, one of the major engine rating lists, lends credence to this position. As of today, November 17th, Fat Fritz sits in seventh place on the CEGT 40/20 list, behind Stockfish, Leela, and Houdini 6. Other private testers with better hardware have gotten somewhat different results. George Tsavadris reports Fat Fritz winning a bullet match (1m + 1s) against SF dev on a Threadripper 2990WX system with two RTX graphics cards. Albert Silver has provided the scores of matches between Fat Fritz, Leela, and Stockfish on a Threadripper machine with dual RTX 2080 GPUs. In games played with a Leela ratio of 1.0, Fat Fritz defeated SF dev 52-48 at 5m + 5s and lost to Leela 55-45 at 3m + 2s. So why the discrepancy in results? Here I hazard an interpretation. Fat Fritz appears to require strong hardware for success in engine-engine matches. This is in part because it is a NN engine, but also because of the way it is configured. Let me treat both in turn.
Here again Stockfish won. The 3m+ 2s match was much closer: 51-49 (20-62-18) in favor of the alpha-beta engine, despite the more favorable hardware situation for Fat Fritz. The 7m + 3s match also went to Stockfish, 56-44 (21-70-9). What does this all mean? My testing shows that Fat Fritz is not dramatically inferior to Leela and the latest versions of Stockfish, but all data from my machine indicates that Leela and Stockfish are stronger. Initial tests from CEGT, one of the major engine rating lists, lends credence to this position. As of today, November 17th, Fat Fritz sits in seventh place on the CEGT 40/20 list, behind Stockfish, Leela, and Houdini 6. Other private testers with better hardware have gotten somewhat different results. George Tsavadris reports Fat Fritz winning a bullet match (1m + 1s) against SF dev on a Threadripper 2990WX system with two RTX graphics cards. Albert Silver has provided the scores of matches between Fat Fritz, Leela, and Stockfish on a Threadripper machine with dual RTX 2080 GPUs. In games played with a Leela ratio of 1.0, Fat Fritz defeated SF dev 52-48 at 5m + 5s and lost to Leela 55-45 at 3m + 2s. So why the discrepancy in results? Here I hazard an interpretation. Fat Fritz appears to require strong hardware for success in engine-engine matches. This is in part because it is a NN engine, but also because of the way it is configured. Let me treat both in turn. 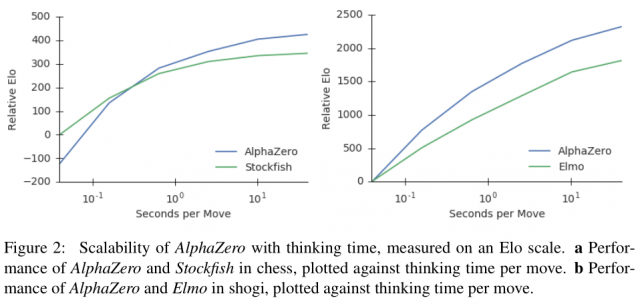 There is a graph in the original AlphaZero preprint showing the relationship between time and relative strength for both AlphaZero and Stockfish. In layman’s terms, it indicates that AlphaZero requires a certain node count (or thinking time) to catch up to Stockfish. While the sample size is small, there is reason to believe that given a certain hardware baseline, additional thinking time benefits the neural net engines like Fat Fritz more than the alpha-beta engines like Stockfish. More: the way that Fat Fritz is configured may damage its results in shorter time controls. If we compare Fat Fritz’s settings with those of Leela, we see that Fat Fritz has a higher Cpuct setting, a higher Cpuctfactor, changes to the FPU settings, and a lower PolicyTemp.
There is a graph in the original AlphaZero preprint showing the relationship between time and relative strength for both AlphaZero and Stockfish. In layman’s terms, it indicates that AlphaZero requires a certain node count (or thinking time) to catch up to Stockfish. While the sample size is small, there is reason to believe that given a certain hardware baseline, additional thinking time benefits the neural net engines like Fat Fritz more than the alpha-beta engines like Stockfish. More: the way that Fat Fritz is configured may damage its results in shorter time controls. If we compare Fat Fritz’s settings with those of Leela, we see that Fat Fritz has a higher Cpuct setting, a higher Cpuctfactor, changes to the FPU settings, and a lower PolicyTemp.


In simple English, this means that Fat Fritz has a wider search and explores rollouts more (Cpuct settings) than does Leela, while it simultaneously narrows that search with the lower PolicyTemp. Wider search may lead to more interesting chess, but it is probably not optimal for short time controls None of this is to explain away the results I got on my machine, only to try to understand how they did not completely cohere with the results of others. Ultimately my sense, based on the above, is that Fat Fritz is competitive with Leela and development versions of Stockfish, but is not quite as strong as they are, especially at fast time controls and on sub-optimal hardware. Of course extensive testing will give better evidence in the weeks to come. (to be continued...) In Part II of this review, posted on Tuesday, we will look at the “subjective tests” I posed to Fat Fritz, investigating some of its games and seeing how it analyzed a number of (admittedly esoteric) positions. We’ll finish off with a consideration of the new features of the GUI and a final evaluation of Fat Fritz and Fritz 17.
Quick links: Fritz 17 at US Chess Sales Getting started with Leela Leela UCI options All Fat Fritz test games in pgn format All Fat Fritz stories on Chessbase.com






Categories
Archives
- July 2025 (24)
- June 2025 (25)
- May 2025 (24)
- April 2025 (29)
- March 2025 (29)
- February 2025 (20)
- January 2025 (24)
- December 2024 (34)
- November 2024 (18)
- October 2024 (35)
- September 2024 (23)
- August 2024 (27)
- July 2024 (44)
- June 2024 (27)
- May 2024 (31)
- April 2024 (51)
- March 2024 (34)
- February 2024 (25)
- January 2024 (26)
- December 2023 (29)
- November 2023 (26)
- October 2023 (37)
- September 2023 (27)
- August 2023 (37)
- July 2023 (47)
- June 2023 (33)
- May 2023 (37)
- April 2023 (45)
- March 2023 (37)
- February 2023 (28)
- January 2023 (31)
- December 2022 (23)
- November 2022 (32)
- October 2022 (31)
- September 2022 (19)
- August 2022 (39)
- July 2022 (32)
- June 2022 (35)
- May 2022 (21)
- April 2022 (31)
- March 2022 (33)
- February 2022 (21)
- January 2022 (27)
- December 2021 (36)
- November 2021 (34)
- October 2021 (25)
- September 2021 (25)
- August 2021 (41)
- July 2021 (36)
- June 2021 (29)
- May 2021 (29)
- April 2021 (31)
- March 2021 (33)
- February 2021 (28)
- January 2021 (29)
- December 2020 (38)
- November 2020 (40)
- October 2020 (41)
- September 2020 (35)
- August 2020 (38)
- July 2020 (36)
- June 2020 (46)
- May 2020 (42)
- April 2020 (37)
- March 2020 (60)
- February 2020 (38)
- January 2020 (45)
- December 2019 (35)
- November 2019 (35)
- October 2019 (42)
- September 2019 (45)
- August 2019 (56)
- July 2019 (44)
- June 2019 (35)
- May 2019 (40)
- April 2019 (48)
- March 2019 (61)
- February 2019 (39)
- January 2019 (30)
- December 2018 (29)
- November 2018 (51)
- October 2018 (45)
- September 2018 (29)
- August 2018 (49)
- July 2018 (35)
- June 2018 (31)
- May 2018 (39)
- April 2018 (31)
- March 2018 (26)
- February 2018 (33)
- January 2018 (30)
- December 2017 (26)
- November 2017 (24)
- October 2017 (30)
- September 2017 (30)
- August 2017 (32)
- July 2017 (27)
- June 2017 (32)
- May 2017 (26)
- April 2017 (37)
- March 2017 (28)
- February 2017 (30)
- January 2017 (27)
- December 2016 (29)
- November 2016 (24)
- October 2016 (32)
- September 2016 (31)
- August 2016 (27)
- July 2016 (24)
- June 2016 (26)
- May 2016 (19)
- April 2016 (30)
- March 2016 (37)
- February 2016 (27)
- January 2016 (33)
- December 2015 (25)
- November 2015 (23)
- October 2015 (16)
- September 2015 (28)
- August 2015 (28)
- July 2015 (6)
- June 2015 (1)
- May 2015 (2)
- April 2015 (1)
- February 2015 (3)
- January 2015 (1)
- December 2014 (1)
- July 2010 (1)
- October 1991 (1)
- August 1989 (1)
- January 1988 (1)
- December 1983 (1)